I recently migrated a side project from DigitalOcean to some dedicated servers. I thought that I would offer some context and examples for why.
DigitalOcean App Platform is a broken mess
The proximal reason I'm migrating this web application to dedicated servers is because I'm getting transient (0.5% to 1%) HTTP 520 errors because I can't reconfigure the inner Cloudflare CDN and load balancer that DigitalOcean imposes on your application when you use App Platform (basically ECS via K8S w/ automatic ingress). I've tried everything including the only toggle available to me on the load balancer, "HTTP2 on/off."
I can fix this by deploying vanilla VPS instances, but if I'm going to afflict myself with setting up an Ansible deployment instead of pushing Docker images to an image repository I'd like to get better value for my money.
Linode 2009 vs. DigitalOcean 2024
In 2009 for $39.99/mo I could get a server with 2 vCPUs and 720 MiB of ram.
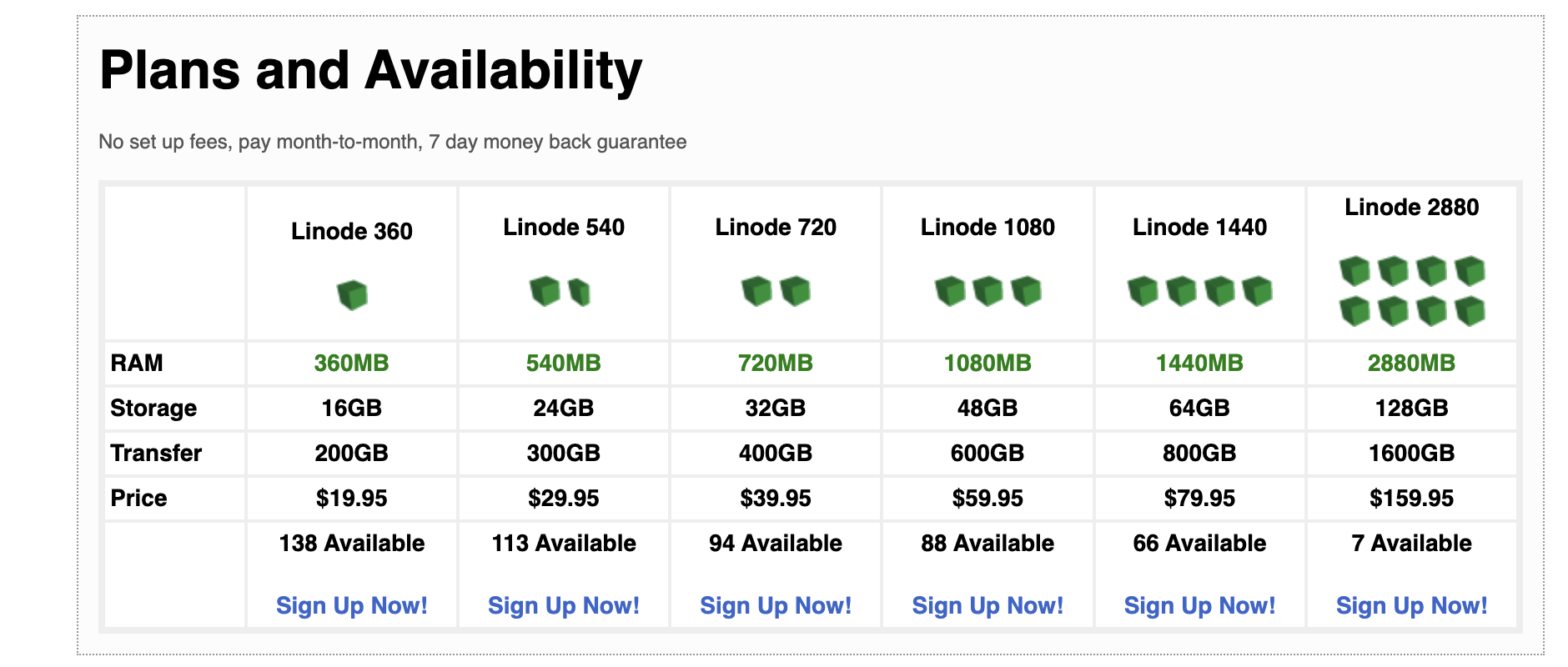
Now this is probably more equivalent to a "shared" instance but I distinctly recall being employed to operate a website with non-trivial traffic on Linode at the time this archive of Linode's website was taken. We didn't even use instances this large for the Django application.
With DigitalOcean in 2024, I'm paying for 1 vCPU / 2 GiB "dedicated" (not really) instances to the tune of…$39/month. And they are not fast. In terms of single-threaded performance, the 1 vCPU is 10x slower than my laptop. And that's before I start accounting for the higher core count on my laptop.
I went with OVH
- 3x $80/mo for a Ryzen 5600X w/ 32 GiB of RAM for the load balancer and web servers
- $150/mo for the database server, AMD Epyc w/ strong single-threaded perf and 8 cores / 16 threads, 64 GiB of RAM, 4x960 GiB NVMe SSDs in soft RAID
$390/mo apart from set-up fees, but I won't need to upgrade this setup for a looooong time and the response times (TTFB) between the browser and the server is 9.5-10x lower from these dedis.
This is about the same or slightly cheaper than what we're paying for DigitalOcean and for my trouble we get something that has 8-10x lower response latency and scales ~50-100x better.
Here's a couple of screenshots from my browser-side performance testing:
DigitalOcean App Platform Droplets:
- Time to first byte: 374 milliseconds
- NTT / Content Download: 22 milliseconds

OVH dedicated server running the same web application:
- Time to first byte: 39 milliseconds
- NTT: 63 milliseconds

Note that the DigitalOcean instance in this example is behind Cloudflare.
For the database, a nightly backup snapshot uploaded somewhere trustworthy is sufficient for now. I plan to automate this using GitLab CI scheduled job runs. Considerably better observability and notification story for no extra work since the site is already built & deployed using GitLab CI.
What's the point?
I know inflation is a thing and some things have improved in terms of performance and the like, but I've been flabbergasted with how much money you have to spend on DigitalOcean to get your app to be even moderately stable for not that much web traffic.
For a sense of how bad things can get even beyond VPS and dedicated providers, consider that the closest thing to these $80 Ryzen 5600X servers in terms of single-threaded performance (remember: ST perf = end-to-end latency hard limit) on Amazon is a z1d. The roughly equivalent size of a z1d EC2 instance would be approximately a 2xlarge and that's over $500/mo on-demand. The "metal" variant of the same is over 3 racks a month.

And that's as good as it gets on AWS. Something about 25% worse in terms of single-threaded performance than my laptop. It gets even worse as you start pricing out and benchmarking things like Aurora for your database.
Modern software is bloated and getting worse
As a general rule for applications that I need to scale, within reason, I want to pay for cores and not more RAM. RAM is expensive, I can usually fit what I'm doing inside a reasonable allocation profile, I just need more cores doing more useful work that aren't bottlenecked by anything else.
In 2009 I was writing a Django application that was basically a home-spun CMS. A little light enhancement with jQuery, but mostly a server-side rendered SSR and the Django ORM to work with the SQL database.
Nowadays developers are doing backflips with ReactJS, Next.js, and a pile of other technologies to render some HTML. Could you solve a problem by just making an RPC (perhaps gRPC?) call to a service behind a load balancer? No no, you've gotta fire up a GraphQL federation provider and slap 200 layers of middleware and plugins into that bad boy. And then add a zero trust / observability sidecar to the K8S pod of any instance that requests access to GraphQL. Because that's Web Scale™.
This is before getting into how exorbitant and extractive the more niche services that AWS and GCP offer can get. Then start looking at a platform like Snowflake for your data and it gets mind-bendingly expensive. I maintain a significant portion of a data platform that would cost ~1000x–10,000x or more to put on Snowflake. It takes a few engineers to develop and operate but if your needs are significant the economics start flipping pretty quickly. You can make your needs less significant and exotic by exercising some discipline in your internal engineering culture as well. Emit less data, schematize and document the data that does get emitted, strict retention windows for lower quality or more speculative data. Store data based on retention category so that data purges are more efficient. etc. etc.
It doesn't have to be like this. It doesn't have to cost this much. It doesn't have to be this inefficient. It's a choice. Choosing otherwise might mean telling some people "no" or "not yet", but it's a choice I think more should consider.
Why is this the default?
Here are some reasons people don't have a good mental model for why "the cloud" (but really this includes VPS providers too) is so expensive:
1. Lack of instrumentation
They don't actually instrument or profile their production applications. Most programmers have never done this to any serious depth.
2. Don't understand hardware
They don't realize almost all VPS instances and EC2 instances are significantly slower in single-threaded performance than the MacBook Air they're using to send emails. Single-threaded performance matters a great deal more to most applications and sets a hard limit on achievable latency. They don't know this because they don't measure anything and move on immediately as soon as the barest interpretation of the product requirements are met.
3. Ignoring cheaper alternatives They don't compare the costs of doing something with AWS (EC2 or a managed offering) to leased dedis. I'm not even suggesting most companies should be spinning up their own datacenter here. A fun exercise that I've done in an interview before is gaming out the cost per user/hour of a streaming service like Netflix on Amazon vs. Hetzner or OVH.
These are some suggestions from past experience, there are other factors I'm not thinking of right now.
What's the steelman argument for using Amazon?
You can build efficient software on AWS, but you have to pick-and-choose what you use and how you use it more carefully than with dedis.
Some things militating in favor of using AWS:
- Vendor integration story is first class. Want to pay Confluent to run a Kafka cluster for you? Good news, AWS is their native home for operating Kafka clusters. You can copy-and-paste this scenario for any number of SaaS technology platforms.
- The network links for the higher tier Amazon instances are phenomenal. This one is a little strange to me because it still isn't cost effective to operate something like a CDN on EC2 instances and very few applications exceed more than 1% of their network link capacity before their server runs out of clock cycles.
- Amazon datacenters are pretty reliable if it isn't us-east-1 (use us-east-2!) and they seem to take multi-AZ availability and failover seriously in their offerings.
- Your SREs already know it.
- Compute on tap, when you need it, however you want it. I ordered the servers yesterday and while all but one server is racked and deployed, I'm still waiting for them to roll out the last server at time of writing.
Also, please stop using AWS Lambda for predictable, foreseeable work that should be held to a budget or planned capacity. Almost none of you have a use-case that actually makes the hassle, complexity, and cost of AWS Lambda make sense.
What's the website?
It's an NBA and WNBA stats website called ShotCreator, I've been working on it with some buddies.
At time of writing, the website is still on DigitalOcean but I will be migrating it soon which should ameliorate the infrequent errors and make the website significantly snappier.
The stack is:
- Database: PostgreSQL
- Database library: diesel_async
- Web framework: Actix backend, Leptos frontend in SSR + Hydrate mode
I'm very happy with OVH's US offerings so far and hope they continue to expand. I'll post updates here if anything goes awry with the migration.
A final plea: Hetzner, please offer dedicated servers in your US datacenters. The "Cloud" instances aren't good enough.